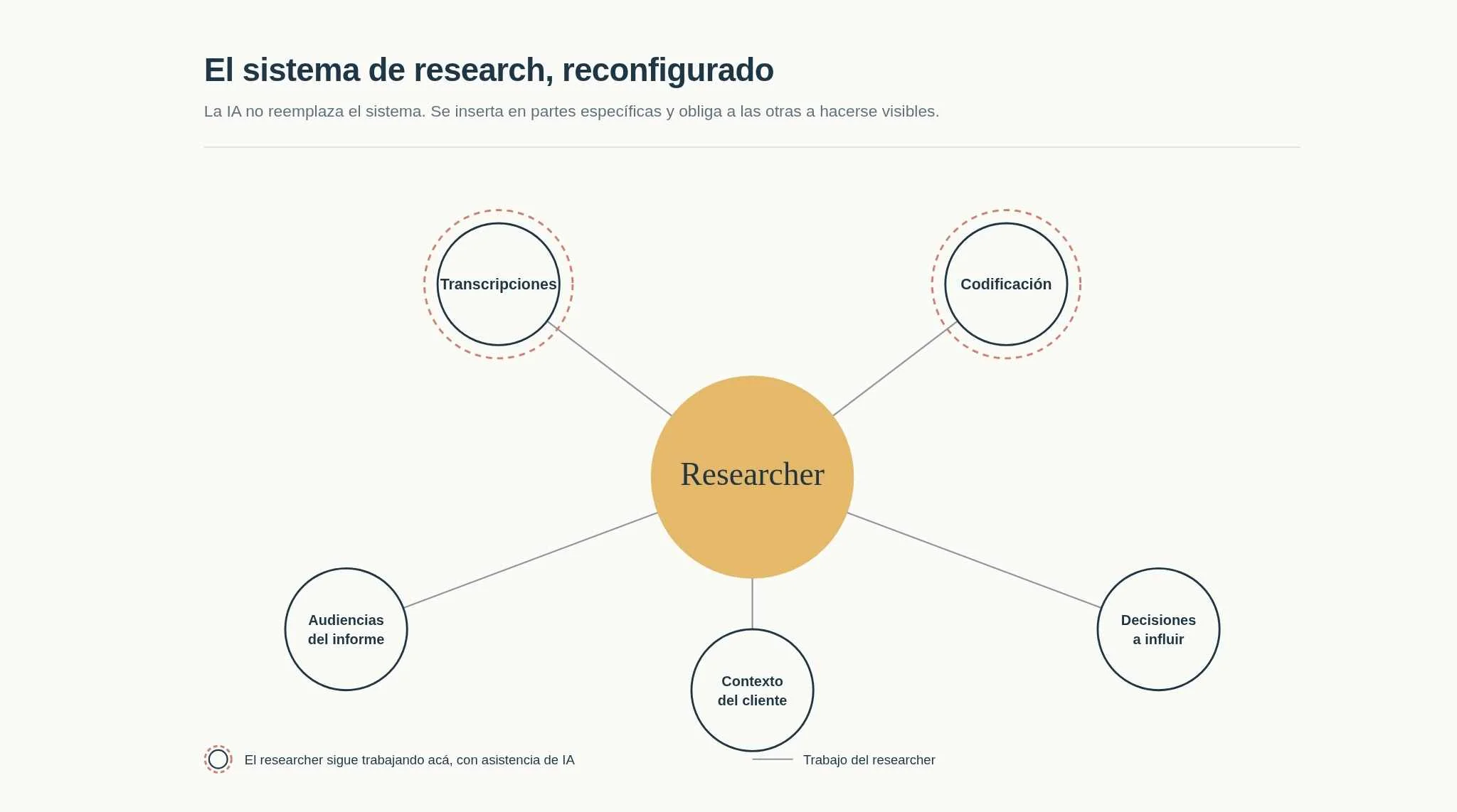
Le pasé a una IA un análisis cualitativo que me había tomado dos meses. Esto es lo que pasó (y lo que sigo procesando)
Ver contenido
Todo empezó por curiosidad. No iba a probar nada, no quería validar la IA ni defender lo cualitativo, mi única hipótesis en este desafío fue que iba a encontrar diferencias, ¿cuáles? ¿de qué tipo de diferencias? eso era lo que iba a averiguar. Solo había visto un challenge de Storytelling with Data hace unos días y pensé: y si paso por un GEM de Gemini ese estudio que hice en 2024, ese de las 21 entrevistas que me tomó dos meses analizar a mano, con hojitas impresas que llevaba para todos lados y códigos que iba armando primero en mi cabeza antes de pasarlos al Excel. Qué podía salir mal, e iba a aprender un montón.
Bueno, aprendí un montón. Pero no de lo que pensaba.
El experimento, contado en crudo
En 2024 hice un estudio para un cliente de una industria, pero sí puedo decir el tamaño del trabajo: 21 entrevistas en profundidad, más una encuesta complementaria que para este ejercicio dejé fuera. En ese momento no tenía software de pago para análisis cualitativo, así que el flujo fue manual de principio a fin. Grabé las sesiones, las volví a escuchar una por una y transcribí todo en Word. Después codifiqué cada entrevista a mano, llevé los códigos a un Excel anotando la fuente de cada código por entrevistado, armé patrones, y de ahí saqué la presentación de resultados.
El análisis combinaba dos lógicas, como suelo trabajar: una deductiva, con precódigos definidos a partir de los objetivos del estudio (más cercana a cómo aprendí a trabajar en UX), y una inductiva más cercana a grounded theory (con la que me formé en psicología y en el magíster, y con la que me siento más cómoda).
Sin contar la ejecución de las entrevistas, que fue otro trabajo completo de coordinación y conducción, el análisis solo me tomó entre 60 y 80 horas. No recuerdo el número exacto, pero fueron dos meses de trabajo, varios fines de semana, y mucho café.
El experimento de hace unos días: armar un GEM en Gemini, conectarlo con las transcripciones, pedirle el mismo análisis. Me tomó 5 horas configurarlo. Tres horas más para que entregara los resultados estructurados en tablas, distinguiendo qué entrevistado dijo qué, como me importaba en 2024.
Los códigos deductivos que me devolvió fueron prácticamente los mismos que los míos. Eso lo esperaba.
Los códigos inductivos, también. Eso no lo esperaba, y es lo que más me removió.
Antes de seguir, algo importante sobre el insumo.
Lo que la IA analizó no era materia prima cualquiera. Eran 21 entrevistas hechas con un propósito específico, con personas reclutadas porque cumplían criterios que importaban para lo que el cliente necesitaba entender. Y a esas 21 las antecedió un trabajo que el GEM no podría haber hecho.
Hubo un kickoff con el cliente para entender qué le dolía, qué hipótesis tenía, qué decisiones quería tomar después con los hallazgos. De ese kickoff salieron los criterios de reclutamiento: a quién buscábamos, por qué a esos y no a otros. Después se planificó la etapa de entrevistas, se diseñó el guion, y se iteró ese guion con el equipo. Las preguntas no eran genéricas, apuntaban a las fricciones específicas que ya habíamos detectado en conversaciones previas. Apuntaban al dolor real, no a uno hipotético.
Y en el camino hacia esas 21 entrevistas se agendaron otras 16 que no se concretaron. Personas que confirmaron y no llegaron. Yo estuve ahí, esperando.
Digo todo esto porque cuando la IA me devolvió códigos casi idénticos a los míos, era fácil pensar “qué impresionante, replicó mi análisis”. Y sí, pero replicó un análisis que se hizo sobre un material que era bueno. Y el material era bueno porque hubo decisiones humanas antes de que existiera siquiera la primera transcripción.
La primera incomodidad
Los códigos inductivos, los que se supone “emergen” de los datos, los que no se van a buscar porque vienen de lo implícito, aparecieron casi idénticos a los que yo construí en 2024. Con énfasis levemente distintos, sí. Pero ahí estaban.
Y al leerlos sentí algo que no anticipé: un desapego raro con los hallazgos.
En 2024 esos códigos eran míos. Sabía de dónde venía cada uno, quién lo había dicho, en qué contexto, por qué se había armado ese y no otro, qué prioridad le asignaba al ponerlo en el reporte. Cuando un código aparecía citado por un entrevistado específico, yo recordaba la pausa antes de decirlo, o la cara, o la frase que vino después.
Al leer los resultados que me entregó la IA, los reconocía, pero no los habitaba. Era como leer el resumen de un libro que escribí yo. Estaba todo. Y al mismo tiempo no estaba nada, esa textura de “yo estuve ahí, yo sé por qué este código pesa más que el otro” no se transfería.
No sé si a otras personas que hacen análisis cualitativo les pasa lo mismo. Yo me quedé mirando el horizonte un buen rato.
El primer aprendizaje que sí puedo nombrar
Acá viene lo que ya pude integrar, aunque haya pasado poco tiempo.
Las 5 horas que me tomó configurar el GEM no fueron 5 horas de “la IA es rápida”. Fueron 5 horas de yo operacionalizando mi propio proceso de análisis cualitativo.
Para que el GEM funcionara tuve que pensar, paso a paso, qué hago primero cuando me siento frente a una transcripción. Qué hago después. Cómo decido qué es un código y qué no. Cuándo paso de códigos a patrones. Cómo distingo un código deductivo de uno inductivo en la práctica, no en la teoría. Cuándo me detengo a releer en vez de seguir avanzando. Qué tipo de entregable produzco y para quién.
Todo eso lo llevaba haciendo años. Pero nunca lo había escrito. Era oficio implícito, decisiones automatizadas por experiencia, una lógica interna que funcionaba pero que no había mirado desde afuera.
El GEM me obligó a mirarla desde afuera. De manera sistemática. Y eso, para alguien que viene de la psicología clínica donde uno mismo es el instrumento, es un movimiento incómodo y revelador a la vez.
Ese fue el aprendizaje claro número uno: la IA no me ahorró 65 horas de trabajo. Me obligó a hacer explícito un trabajo que llevaba años haciendo implícito. Y ahora que está explícito, lo veo distinto. No mejor ni peor, distinto.
Lo que la IA no hizo
Acá viene el segundo aprendizaje, y es el que más me importa para seguir trabajando con clientes.
Cuando entregué los resultados en 2024, no hice un solo informe. Hice tres miradas dentro de la misma presentación. Una para stakeholders del cliente, con énfasis en lo estratégico y en cómo los hallazgos afectaban decisiones de negocio. Otra para el equipo de producto, con foco en oportunidades concretas de iteración. Y otra para ingeniería, con énfasis en los hallazgos que tocaban arquitectura técnica y feasibilidad. Misma data, tres lecturas, tres niveles de abstracción.
El GEM, por defecto, me entregó un único resultado, plano, orientado principalmente a producto. No porque sea limitada, sino porque nunca le di ese contexto. Nunca le dije quiénes iban a leer esto, qué decisiones iban a tomar a partir de los hallazgos, qué nivel de abstracción servía para cada audiencia. Tampoco vio las pantallas del producto, ni los flujos, ni el contexto del equipo. Y eso era información que yo sí tenía y que usé sin pensar al armar la presentación.
Hay algo importante ahí: el análisis cualitativo es solo una parte del trabajo. La otra parte, igual de pesada, es la interpretación situada, leer los hallazgos en función de quién va a usarlos, para qué, en qué contexto, con qué nivel de poder de decisión. Eso es lo que un cliente B2B contrata cuando contrata investigación. No la codificación, sino la lectura de los datos.
La IA puede asistir la codificación. La interpretación situada, hasta donde he visto, sigue siendo trabajo humano. Y no porque la IA sea “limitada”, sino porque el contexto del cliente, las dinámicas internas, los equipos, las prioridades en tensión, son información que la IA simplemente no tiene. Yo tampoco la tenía completa, pero tenía mucha más.

Lo que sigo procesando
Hasta acá los aprendizajes nítidos. Lo que sigue es lo que aún me remueve y todavía no integro del todo.
El desapego. Sigo sin saber qué hacer con la sensación de leer hallazgos propios sin habitarlos. No me había pasado antes. Tengo una hipótesis: que cuando uno hace el análisis a mano, el proceso mismo es parte del conocimiento. No es solo qué encontraste, sino cómo lo encontraste, qué pensaste al leer cierta cita, qué descartaste y por qué. Cuando la IA hace ese proceso, los resultados llegan limpios pero sin la memoria del trayecto. Y esa memoria del trayecto era, sin que yo lo supiera, parte importante de cómo defendía después los hallazgos en una reunión.
No sé si esto es un problema a resolver o una característica nueva a la que voy a adaptarme. Por ahora lo nombro y lo dejo en pregunta.
Después de publicar este post, me encontré con un paper que le pone nombre a lo que estaba describiendo. Ugaya-Mazza, Morita y Wallace, investigadores de la Universidad de Waterloo, publicaron The Shape of Agency, un estudio sobre qué pasa con el sentido de control, autoría e interpretación de investigadores cualitativos cuando usan herramientas computacionales para analizar datos. Lo que ellos examinan, y lo que yo estaba experimentando sin saberlo, se llama personal agency del investigador, un concepto que toman de Eichner y que desglosan en cuatro dimensiones. Al leerlas me di cuenta de que cada una tocaba algo de lo que me había pasado con el GEM.
Dominio de la acción (mastery of action): sentir que tus acciones se reflejan en el resultado. Cuando codificaba a mano, cada código pasaba por mi cabeza antes de existir en el Excel. Lo pensaba, lo dudaba, lo descartaba, lo volvía a incluir. El GEM me devolvió códigos que yo reconocía pero que no habían pasado por ese proceso, llegaron limpios, sin la fricción del hacer. Los participantes del estudio de Ugaya-Mazza reportan lo mismo: cuando el proceso analítico se vuelve opaco o automatizado, se pierde la sensación de que uno produjo esos resultados. Una participante del estudio lo dijo: “No querría que analizara nada por mí porque entonces me vuelvo obsoleta.” No es miedo a la tecnología.
Dominio de la elección (mastery of choice): poder ejercer decisiones dentro de restricciones claras. Acá hay algo que me hizo repensar las 5 horas que pasé configurando el GEM. Ese proceso fue, en cierto modo, un ejercicio forzado de hacer explícitas decisiones que antes eran tácitas (y en eso se parece a lo que describí como “el primer aprendizaje” más arriba). Pero una vez que el GEM procesó todo, las decisiones intermedias: qué código pesa más, qué descarto, qué reagrupo, qué priorizo, ya no eran mías. Y esa es la tensión que el paper identifica: demasiada automatización elimina la elección; pero demasiada libertad sin guía tampoco sirve, produce parálisis. Lo que los participantes del estudio pedían era algo intermedio: herramientas que sugieran opciones pero que dejen la decisión final en el investigador. Una de las participantes lo resume así: “Prefiero un software que me dé orientación antes que uno con libertad completa pero sin asistencia.”
Dominio de la narrativa (mastery of narrative): poder construir la historia que cuentan los datos. Esta dimensión es la que más conecta con mi experiencia de las tres lecturas del informe, stakeholders, producto, ingeniería, que describí en la sección anterior. Decidir qué historia contar a quién, con qué énfasis, qué dejar fuera y qué subir de nivel, no es decoración posterior al análisis. Es análisis. Y es algo que la IA, sin el contexto situado del proyecto, no puede hacer. El paper hace una observación que me quedó resonando: las visualizaciones de datos no son representaciones neutrales de información. Un gráfico de líneas implica progresión temporal, un diagrama de agrupamiento sugiere proximidad relacional, un árbol jerárquico comunica estructura. Cuando el investigador puede elegir y manipular esas formas, mantiene la autoría sobre la narrativa analítica. Cuando recibe los resultados ya empaquetados (como me pasó a mí con el GEM), esa autoría se diluye. Los participantes del estudio describían las visualizaciones como herramientas para “hacer una historia” con los datos, lo cual es exactamente lo que yo hago cuando paso de códigos a patrones a presentación, solo que lo hacía sin llamarlo “dominio de la narrativa”.
Dominio del espacio (mastery of space): navegar el espacio de trabajo analítico. Mis hojas impresas que llevaba para todos lados, el Excel con los códigos por entrevistado, el ir y venir entre transcripciones y notas al margen, eso era un espacio que yo habitaba. No solo metafóricamente: movía papeles, reordenaba post-its, iba de una transcripción a otra buscando un fragmento que recordaba a medias. El GEM me devolvió los resultados en un espacio que no era mío. No podía mover cosas, reagrupar, desordenar para reordenar. Los participantes del estudio describen exactamente esta fricción: una de ellas prefería pizarras, papel o su iPad porque ahí podía ser “desordenada” y mover elementos libremente. Cuando las herramientas digitales restringen esa libertad de movimiento, la sensación de agencia se reduce, incluso si los resultados son correctos.
Pero hay una distinción del paper que me parece la más importante de todas, y que creo aplica a cómo muchos estamos usando IA para análisis cualitativo: transparencia no es lo mismo que agencia. Puedo entender perfectamente cómo el GEM llegó a sus códigos, le di las instrucciones, puedo rastrear su lógica, puedo verificar las citas. Eso es transparencia. Pero eso no restaura la sensación de que esos códigos son míos. La agencia, según el paper, depende de si puedo actuar dentro del espacio representacional, reorganizar elementos, reencuadrar clusters, redirigir trayectorias analíticas. Cuando la interacción con la IA ocurre solo vía prompts de chat (que es exactamente como usé el GEM), la estructura analítica queda implícita, encerrada en la conversación. En cambio, cuando tienes una visualización que puedes manipular, esa estructura se externaliza y se vuelve negociable. El paper lo dice de una forma que me parece muy clara: que una explicación del razonamiento del modelo puede clarificar cómo se produjo un resultado, pero no necesariamente restaura el dominio de la acción ni de la narrativa.
Eso me da una pista para algo que todavía no he resuelto en la práctica: quizás parte de lo que se pierde al usar IA para codificar no se recupera solo agregando más contexto al prompt (que es lo que yo hice después del experimento, y que describo en “Lo que cambié en mi práctica”). Quizás lo que falta es un espacio visual donde pueda tomar los códigos que la IA generó y moverlos, reagruparlos, descartarlos, hacerlos míos a través del acto de manipularlos. No estoy segura de que las herramientas actuales lo permitan bien integrar la IA generativa con manipulación directa del espacio analítico. Pero al menos ahora sé cómo se llama lo que estaba buscando: agencia. Y saber cómo se llama es el primer paso para diseñar mejor alrededor de eso.
(Hay algo de ironía en que una UX Researcher descubra a través de un experimento con IA lo mismo que otros investigadores encontraron estudiando a investigadores cualitativos. Pero así funciona esto: primero lo vives, después lo lees, y lo leído le pone nombre a lo vivido.)
La pregunta gremial. Esta es la más incómoda y la dejo al final porque no la tengo resuelta. Cuando empecé a escribir esto, pensé en no publicarlo. Pensé que iba a sonar como traición a otras personas que trabajamos cualitativamente, que están pasando por la misma pregunta sin decirlo en voz alta. Pensé que iba a sonar como “soy reemplazable”, lo cual no es lo que estoy diciendo, pero podía leerse de ese modo.
Sigo pensando que el riesgo existe. Pero también pienso que aunque queramos cerrar los ojos esto no desaparece. Si quienes hacemos cualitativo no escribimos sobre esto, la conversación va a quedar en manos de quienes nunca hicieron análisis cualitativo, y la respuesta de mercado va a ser una caricatura. Prefiero que esté esta voz, aunque sea procesando, antes que solo la voz de quien vende cursos de “IA reemplaza al researcher”.
Lo que cambié en mi práctica desde entonces
Desde este experimento, dos cosas cambiaron en cómo trabajo:
Una. Estoy escribiendo mi proceso. Como documento de trabajo interno. Si tuve que destilar mi flujo para que un GEM lo siguiera, tiene sentido tenerlo documentado para mí también. Para usarlo en otros estudios, para iterarlo, para que en algún momento pueda enseñarlo mejor que ahora.
Dos. Cuando uso IA en análisis, ahora lo pienso como “yo lo haría”, no como lo que espero que la IA haga por mí. No sé si se entiende esa diferencia. Le doy contexto del cliente, las audiencias del informe, las decisiones que se van a tomar con los hallazgos. Antes no lo hacía porque asumía que la IA solo necesitaba los datos. Ahora entiendo que la IA, sin contexto situado, entrega análisis técnicamente correcto pero estratégicamente plano. Ese contexto sigue siendo mi trabajo. Y probablemente sea cada vez más mi trabajo principal.
Hay una frase de Cole Knaflic, la autora del challenge de Storytelling with Data que disparó todo esto, que me quedó dando vueltas. En el video Data Storytelling in the Age of AI, hacia el minuto 2:36, ella dice: “What AI still can’t do, however, is decide what matters. AI doesn’t know what’s right for this specific audience at this specific moment in time.” Lo que la IA todavía no puede hacer es decidir qué importa. La IA no sabe qué es lo correcto para esta audiencia específica, en este momento específico.
Creo que con el análisis cualitativo pasa lo mismo, pero un nivel más adentro. La IA puede codificar pero no puede decidir qué historia están contando los códigos, ni para quién, ni con qué énfasis. Eso sigue (aún) siendo nuestro.
Fuentes
- Cole Nussbaumer Knaflic. Data Storytelling in the Age of AI: What is the human role when AI can generate anything? [Video, YouTube]. Cita textual del minuto 2:36. Enlace:
- Storytelling with Data Community. May 2026 Challenge: Human + AI — Re-analyzing the same interviews two years apart. Enlace: https://community.storytellingwithdata.com/challenges/may-2026-human-ai/re-analyzing-the-same-interviews-two-years-apart-h
- Luka Ugaya Mazza, Plinio Morita y James R. Wallace. The Shape of Agency: Designing for Personal Agency in Qualitative Data Analysis. University of Waterloo. El paper examina cómo la agencia personal — dominio de la acción, la elección, la narrativa y el espacio — puede funcionar como lente de diseño para herramientas de análisis cualitativo computacional. Enlace: https://cs.uwaterloo.ca/~dvogel/gi2026/papers/1043a.pdf
Artículos relacionados

IA y UX Research: cómo voy integrando la IA a mi trabajo (y los recursos que me han servido)
Guía Completa de Análisis Temático: 7 Fases para Aprender Análisis Cualitativo
