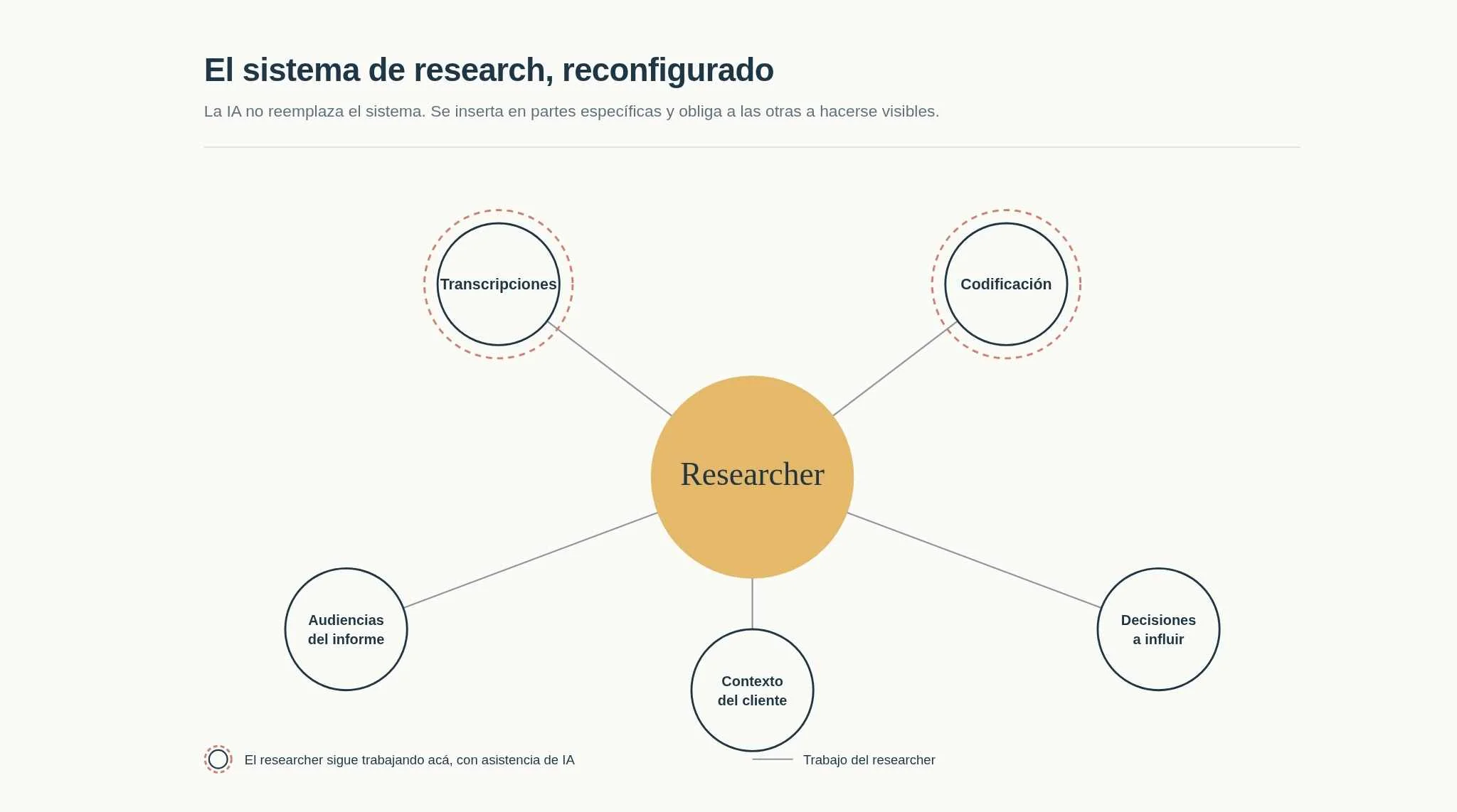
I gave an AI a qualitative analysis that had taken me two months. Here's what happened (and what I'm still processing)
View contents
It started out of curiosity. I wasn’t trying to prove anything, I didn’t want to validate AI or defend qualitative work; my only hypothesis going into this challenge was that I’d find differences. Which ones? What kind of differences? That was what I was going to find out. I had just seen a Storytelling with Data challenge a few days earlier and thought: what if I ran that 2024 study through a Gemini GEM, the one with 21 interviews that took me two months to analyze by hand, with printed sheets I carried everywhere and codes I would first build in my head before moving them to Excel. What could go wrong, and I’d learn a lot.
Well, I learned a lot. Just not what I expected to learn.
The experiment, told raw
In 2024 I ran a study for a client in an industry, but I can say the size of the work: 21 in-depth interviews, plus a complementary survey I left out of this exercise. At the time I didn’t have paid software for qualitative analysis, so the workflow was manual from start to finish. I recorded the sessions, listened to each one again, and transcribed everything in Word. Then I coded each interview by hand, moved the codes into Excel noting the source of each code by interviewee, built patterns, and from there produced the final presentation.
The analysis combined two logics, as I usually work: a deductive one, with pre-codes defined from the study’s objectives (closer to how I learned to work in UX), and an inductive one closer to grounded theory (the one I trained in through psychology and my master’s, and the one I feel most comfortable with).
Without counting the interview execution itself, another full job of coordination and facilitation, the analysis alone took me between 60 and 80 hours. I don’t remember the exact number, but it was two months of work, several weekends, and a lot of coffee.
The experiment a few days ago: build a GEM in Gemini, connect it to the transcripts, ask for the same analysis. It took me 5 hours to set up. Three more hours for it to return the results structured in tables, distinguishing which interviewee said what, the way it mattered to me in 2024.
The deductive codes it returned were practically the same as mine. I expected that.
The inductive codes, too. I didn’t expect that, and it’s what shook me most.
Before I go on, something important about the input.
What the AI analyzed wasn’t just any raw material. It was 21 interviews done with a specific purpose, with people recruited because they met criteria that mattered for what the client needed to understand. And those 21 were preceded by work the GEM could never have done.
There was a kickoff with the client to understand what hurt, what hypotheses they had, what decisions they wanted to make later with the findings. From that kickoff came the recruitment criteria: who we were looking for, why those people and not others. Then the interview phase was planned, the script was designed, and that script was iterated with the team. The questions weren’t generic: they targeted specific frictions we had already detected in previous conversations. They aimed at real pain, not hypothetical pain.
And on the road to those 21 interviews, another 16 were scheduled that never happened. People who confirmed and didn’t show. I was there, waiting.
I’m saying all this because when the AI gave me back codes almost identical to mine, it was easy to think “how impressive, it replicated my analysis”. And yes, but it replicated an analysis done on material that was good. And the material was good because there were human decisions before the first transcript even existed.
The first discomfort
The inductive codes, the ones that are supposed to “emerge” from the data, the ones you don’t go looking for because they come from the implicit, appeared almost identical to the ones I built in 2024. With slightly different emphasis, yes. But there they were.
And reading them, I felt something I didn’t anticipate: a strange detachment from the findings.
In 2024 those codes were mine. I knew where each one came from, who had said it, in what context, why I had built that one and not another, what priority I assigned to it when placing it in the report. When a code was cited by a specific interviewee, I remembered the pause before they said it, or the face, or the sentence that followed.
Reading the results the AI handed me, I recognized them but didn’t inhabit them. It was like reading the summary of a book I had written. Everything was there. And at the same time nothing was there, that texture of “I was there, I know why this code weighs more than the other one” wasn’t transferring.
I don’t know if other people who do qualitative analysis experience the same thing. I sat staring at the horizon for a good while.
The first learning I can actually name
Here comes what I’ve been able to integrate, even though not much time has passed.
The 5 hours it took me to set up the GEM weren’t 5 hours of “AI is fast”. They were 5 hours of me operationalizing my own qualitative analysis process.
For the GEM to work I had to think, step by step, what I do first when I sit down in front of a transcript. What I do next. How I decide what counts as a code and what doesn’t. When I move from codes to patterns. How I distinguish a deductive code from an inductive one in practice, not in theory. When I stop to re-read instead of moving forward. What kind of deliverable I produce and for whom.
I had been doing all of that for years. But I had never written it down. It was implicit craft, decisions automated by experience, an internal logic that worked but that I had never looked at from the outside.
The GEM forced me to look at it from the outside. Systematically. And that, for someone coming from clinical psychology where you yourself are the instrument, is an uncomfortable and revealing move at the same time.
That was clear learning number one: AI didn’t save me 65 hours of work. It forced me to make explicit a kind of work I had been doing implicitly for years. And now that it’s explicit, I see it differently. Not better or worse, just differently.
What the AI didn’t do
Here comes the second learning, and it’s the one that matters most to me for working with clients going forward.
When I delivered the results in 2024, I didn’t make a single report. I made three readings inside the same presentation. One for the client’s stakeholders, with emphasis on the strategic and on how the findings affected business decisions. Another for the product team, focused on concrete iteration opportunities. And another for engineering, with emphasis on findings that touched technical architecture and feasibility. Same data, three readings, three levels of abstraction.
The GEM, by default, gave me a single result, flat, oriented mostly toward product. Not because it’s limited, but because I never gave it that context. I never told it who was going to read this, what decisions would be made from the findings, what level of abstraction worked for each audience. It also didn’t see the product screens, or the flows, or the team’s context. And that was information I did have and that I used without thinking when I built the presentation.
There’s something important there: qualitative analysis is only one part of the work. The other part, just as heavy, is the situated interpretation: reading the findings in relation to who will use them, for what, in what context, with what level of decision-making power. That’s what a B2B client buys when they buy research. Not the coding, but the reading of the data.
AI can assist with the coding. The situated interpretation, as far as I’ve seen, remains human work. And not because AI is “limited”, but because the client’s context, the internal dynamics, the teams, the priorities in tension: that’s information the AI simply doesn’t have. I didn’t have it complete either, but I had a lot more.

What I’m still processing
That’s the sharp learnings. What follows is what still unsettles me and I haven’t fully integrated yet.
The detachment. I still don’t know what to do with the feeling of reading my own findings without inhabiting them. It hadn’t happened to me before. I have a hypothesis: that when you do the analysis by hand, the process itself is part of the knowledge. It’s not just what you found, but how you found it, what you thought when reading a certain quote, what you discarded and why. When AI does that process, the results arrive clean but without the memory of the journey. And that memory of the journey was, without my knowing it, an important part of how I later defended the findings in a meeting.
I don’t know if this is a problem to solve or a new feature I’m going to adapt to. For now I name it and leave it as a question.
After publishing this post, I came across a paper that names what I had been describing. Ugaya-Mazza, Morita, and Wallace, researchers at the University of Waterloo, published The Shape of Agency, a study about what happens to qualitative researchers’ sense of control, authorship, and interpretation when they use computational tools to analyze data. What they examine, and what I was experiencing without knowing it, is called the researcher’s personal agency, a concept they take from Eichner and break down into four dimensions. Reading them, I realized each one touched on something that had happened to me with the GEM.
Mastery of action (dominio de la acción): feeling that your actions are reflected in the result. When I coded by hand, every code passed through my head before it existed in the Excel. I thought it, I doubted it, I discarded it, I included it again. The GEM gave me back codes I recognized but that hadn’t gone through that process, they arrived clean, without the friction of doing. The participants in Ugaya-Mazza’s study report the same thing: when the analytic process becomes opaque or automated, you lose the sense that you produced those results. One participant in the study put it plainly: “I wouldn’t want it to analyze anything for me because then I become obsolete.” It’s not fear of technology.
Mastery of choice (dominio de la elección): being able to exercise decisions within clear constraints. Here there’s something that made me rethink the 5 hours I spent configuring the GEM. That process was, in a way, a forced exercise in making explicit decisions that used to be tacit (and in that it resembles what I described as “the first learning” above). But once the GEM processed everything, the intermediate decisions: which code weighs more, what I discard, what I regroup, what I prioritize, were no longer mine. And that’s the tension the paper identifies: too much automation eliminates choice; but too much freedom without guidance doesn’t work either, it produces paralysis. What the study participants asked for was something in between: tools that suggest options but leave the final decision to the researcher. One of the participants sums it up like this: “I prefer software that gives me guidance rather than one with complete freedom but no assistance.”
Mastery of narrative (dominio de la narrativa): being able to construct the story the data tells. This dimension is the one that connects most with my experience of the three readings of the report, stakeholders, product, engineering, that I described in the previous section. Deciding which story to tell to whom, with what emphasis, what to leave out and what to elevate, is not decoration after the analysis. It is analysis. And it’s something AI, without the situated context of the project, cannot do. The paper makes an observation that stayed with me: data visualizations are not neutral representations of information. A line chart implies temporal progression, a clustering diagram suggests relational proximity, a hierarchical tree communicates structure. When the researcher can choose and manipulate those forms, they retain authorship over the analytic narrative. When they receive the results already packaged (as happened to me with the GEM), that authorship dilutes. The study participants described visualizations as tools to “make a story” with their data, which is exactly what I do when I go from codes to patterns to presentation, only I was doing it without calling it “mastery of narrative.”
Mastery of space (dominio del espacio): navigating the analytic workspace. My printed sheets that I carried everywhere, the Excel with the codes by interviewee, the back and forth between transcripts and margin notes, that was a space I inhabited. Not only metaphorically: I moved papers, rearranged post-its, went from one transcript to another looking for a fragment I half-remembered. The GEM gave me back the results in a space that wasn’t mine. I couldn’t move things, regroup, mess things up in order to reorder them. The study participants describe exactly this friction: one of them preferred whiteboards, paper, or her iPad because there she could be “messy” and move elements freely. When digital tools restrict that freedom of movement, the sense of agency is reduced, even if the results are correct.
But there’s a distinction in the paper that seems to me the most important of all, and that I think applies to how many of us are using AI for qualitative analysis: transparency is not the same as agency. I can perfectly understand how the GEM arrived at its codes, I gave it the instructions, I can trace its logic, I can verify the quotes. That’s transparency. But that doesn’t restore the sense that those codes are mine. Agency, according to the paper, depends on whether I can act within the representational space, reorganize elements, reframe clusters, redirect analytic trajectories. When the interaction with AI happens only via chat prompts (which is exactly how I used the GEM), the analytic structure stays implicit, locked inside the conversation. By contrast, when you have a visualization you can manipulate, that structure is externalized and becomes negotiable. The paper puts it in a way that seems very clear to me: that an explanation of model reasoning may clarify how a result was produced, but does not necessarily restore mastery of action or narrative.
That gives me a clue for something I still haven’t resolved in practice: maybe part of what’s lost when using AI to code isn’t recovered just by adding more context to the prompt (which is what I did after the experiment, and which I describe in “What I changed in my practice”). Maybe what’s missing is a visual space where I can take the codes the AI generated and move them, regroup them, discard them, make them mine through the act of manipulating them. I’m not sure current tools allow that well, integrating generative AI with direct manipulation of the analytic space. But at least now I know what to call what I was looking for: agency. And knowing what to call it is the first step to designing better around it.
(There’s some irony in a UX Researcher discovering through an experiment with AI the same thing other researchers found by studying qualitative researchers. But that’s how this works: first you live it, then you read it, and what you read names what you lived.)
The guild question. This is the most uncomfortable one and I leave it for last because I haven’t resolved it. When I started writing this, I thought about not publishing it. I thought it would sound like a betrayal of other people who work qualitatively, who are going through the same question without saying it out loud. I thought it would sound like “I’m replaceable”, which is not what I’m saying, but could be read that way.
I still think the risk exists. But I also think that even if we want to close our eyes, this doesn’t go away. If those of us who do qualitative work don’t write about this, the conversation will be left in the hands of people who never did qualitative analysis, and the market response will be a caricature. I’d rather this voice be there, even while processing, than only the voice of someone selling courses on “AI replaces the researcher”.
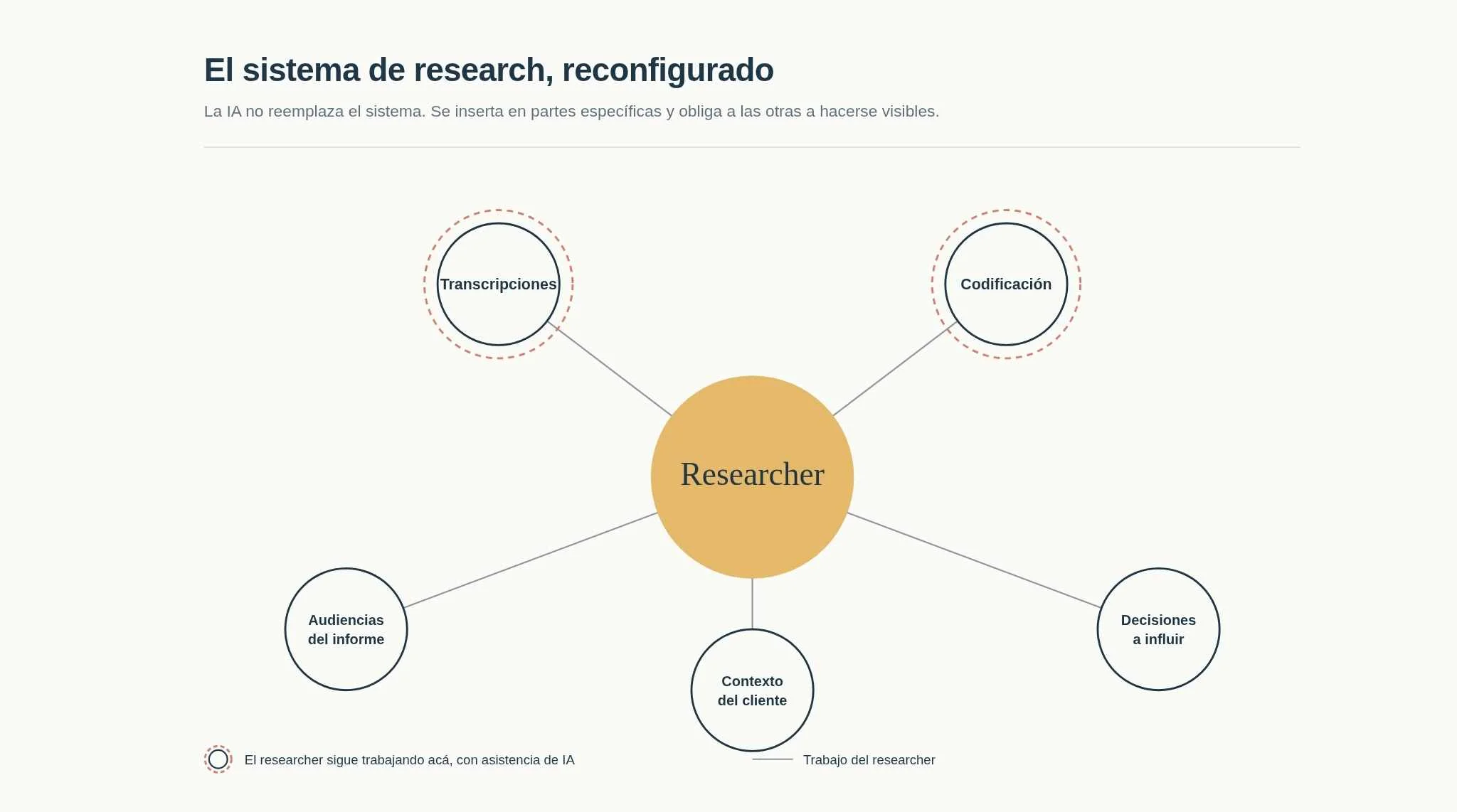
What I changed in my practice since then
Since this experiment, two things have changed in how I work:
One. I’m writing down my process. As an internal working document. If I had to distill my workflow for a GEM to follow it, it makes sense to have it documented for myself too. To use in other studies, to iterate on it, so that at some point I can teach it better than I can now.
Two. When I use AI for analysis, I now think of it as “how I would do it”, not as what I expect the AI to do for me. I’m not sure that distinction comes through. I give it client context, the audiences for the report, the decisions that will be made from the findings. I didn’t do that before because I assumed the AI only needed the data. Now I understand that AI, without situated context, delivers analysis that’s technically correct but strategically flat. That context is still my job. And it will probably be increasingly my main job.
There’s a phrase from Cole Knaflic, the author of the Storytelling with Data challenge that triggered all of this, that keeps echoing for me. In the video Data Storytelling in the Age of AI, around minute 2:36, she says: “What AI still can’t do, however, is decide what matters. AI doesn’t know what’s right for this specific audience at this specific moment in time.”
I think the same goes for qualitative analysis, but one level deeper. AI can code, but it can’t decide what story the codes are telling, or for whom, or with what emphasis. That (still) remains ours.
Sources
- Cole Nussbaumer Knaflic. Data Storytelling in the Age of AI: What is the human role when AI can generate anything? [Video, YouTube]. Direct quote from minute 2:36. Link:
- Storytelling with Data Community. May 2026 Challenge: Human + AI — Re-analyzing the same interviews two years apart. Link: https://community.storytellingwithdata.com/challenges/may-2026-human-ai/re-analyzing-the-same-interviews-two-years-apart-h
- Luka Ugaya Mazza, Plinio Morita, and James R. Wallace. The Shape of Agency: Designing for Personal Agency in Qualitative Data Analysis. University of Waterloo. The paper examines how personal agency, mastery of action, choice, narrative, and space, can serve as a design lens for computational qualitative data analysis tools. Link: https://cs.uwaterloo.ca/~dvogel/gi2026/papers/1043a.pdf